On the complexity of binary searches
I would like to share here an alternative way to find the complexity of the binary search algorithm. A Binary Search is an algorithm to search for an element through an ordered list, and is remarkable for both its simplicity in terms of implementation and its “worst-case” complexity. By complexity I mean the dependence of the number of iterations with the number of elements in the list. Concerning the number of comparisons, no search algorithm based on comparisons outperforms binary searches on average or in their worst-case scenario (see The Art of Computer Programming, vol 3). The method I share here is an extension of what is commonly presented in books and classes.
Before we go on, let me thank Brenno Barbosa for his review and comments.
It is very easy to define the binary search algorithm, and it starts with the assumption that the list is ordered. Let’s say we are looking for an element $e$. First, the list is divided into two. The element in the middle, say $m$, is then compared to $e$: if $m > e$, then $e$ might be in the first half of the list; if $m < e$, then e might be in the second half; if $m=e$, then we are done with our search. It is evident now that the central operations in this algorithm are the several comparisons performed during the search.
As a quick review, find below a minimal Python module implementing a Binary Search. The visualization at the beginning of the post is a common way to represent it. This is the script I used to create this animation.
The challenge then is to be able to calculate how the number $C(n)$ of comparisons depends on the total length of the list, $n$, in the worst case. From the recursive nature of the algorithm, we can write the number of comparisons as function of the number of operations needed for a list of length $n/2$,
The floor function $\lfloor \cdot \rfloor$ in $C(n)$ fixes cases where $n$ is not even. For an empty list, there are no comparisons, i.e. $C(0) = 0$. Also, if there is only one element in the list, then there is of course only one iteration. Therefore, $C(1)=1$. These are the boundary conditions for the recursion above.
You can try with a few examples for yourself, with lists of two or three elements.
Solving for powers of two
This first particular case is very easy to find and is often presented in Algorithms & Data Structures classes. Let’s begin by assuming that $n$ is a power of $2$, i.e., $n=2^k$ with $k\in \mathbb{Z}$. This assumption simplifies $C(n)$ into
for any $p<n$. Although it may not be crystal clear yet, this is an arithmetic progression with a common difference of 1. To better visualize that, let $f(k) = C(2^k)$, then the above equation becomes $f(k) = k + 1$. Finally, substituting $p=k$ in the last
Inverting $k$ as function of $n$ and plugging in the equation above, we have
The last result holds whenever $n$ is a power of two. Some textbooks even skip this proof, so I tried to make each step very clear. Remember that we are assuming, because we went all the way to $C(1)$, which is equivalent to having a single last element to be checked - i.e., the deepest level in the search was reached. In other words, this is an upper bound to the actual complexity. For numerical experiments, go to the end of this post.
Solving the general case
If $n$ is not exactly a power of $2$, it still can be written as $n = 2^k + q$ with $k,q \in \mathbb{Z}$. Indeed, we can set
or $0 < q < 2^k$. If this condition is not true, then $k$ should be $k+1$, and $q$ can be re-evaluated in the interval $0 < q < 2^{k+1}$. This means that the factor $q$ is the smallest possible correction of $n$ from a power of $2$. Then, we can write the complexity as
Let’s define $q_0 = q$ and
Because $\lfloor x + n \rfloor = \lfloor x \rfloor + n$ if $n$ is integer (see identities here) and because $2^k/2 = 2^{k-1}$ is integer, we can split the sum inside the floor function as follows:
Thus, combining these last three pieces of information, we have
In particular, when $p=k$,
which leads us to
and therefore
And that is it: This is the general result and extends the special case when $n$ is a power of $2$. Interestingly, the only difference is that now we take the floor of $log_2 (n)$. In other words, the worst-case complexity of a binary search in any list with size $2^k < n \leq 2^{k+1}$ should be the same. Although it is very common to present only the first part of this demonstration in classes and books, assuming that $n=2^k$, it is indeed quite easy to generalize the result for any other integer. I particularly think this is an interesting argument that may give an insight into other derivations. This is, of course, closely related to the Master Theorem from Analysis of Algorithms.
How about wrapping this with a numerical test?
This expression for $C(n)$ is indeed very simple, and a great exercise is to test it numerically. Below we have results of numerical simulations with randomly created lists of several different sizes, the average complexity for each size (dark green line) and the comparison with the calculated formula (red line), $1 + \left\lfloor \log_2 \left( n \right) \right\rfloor$.
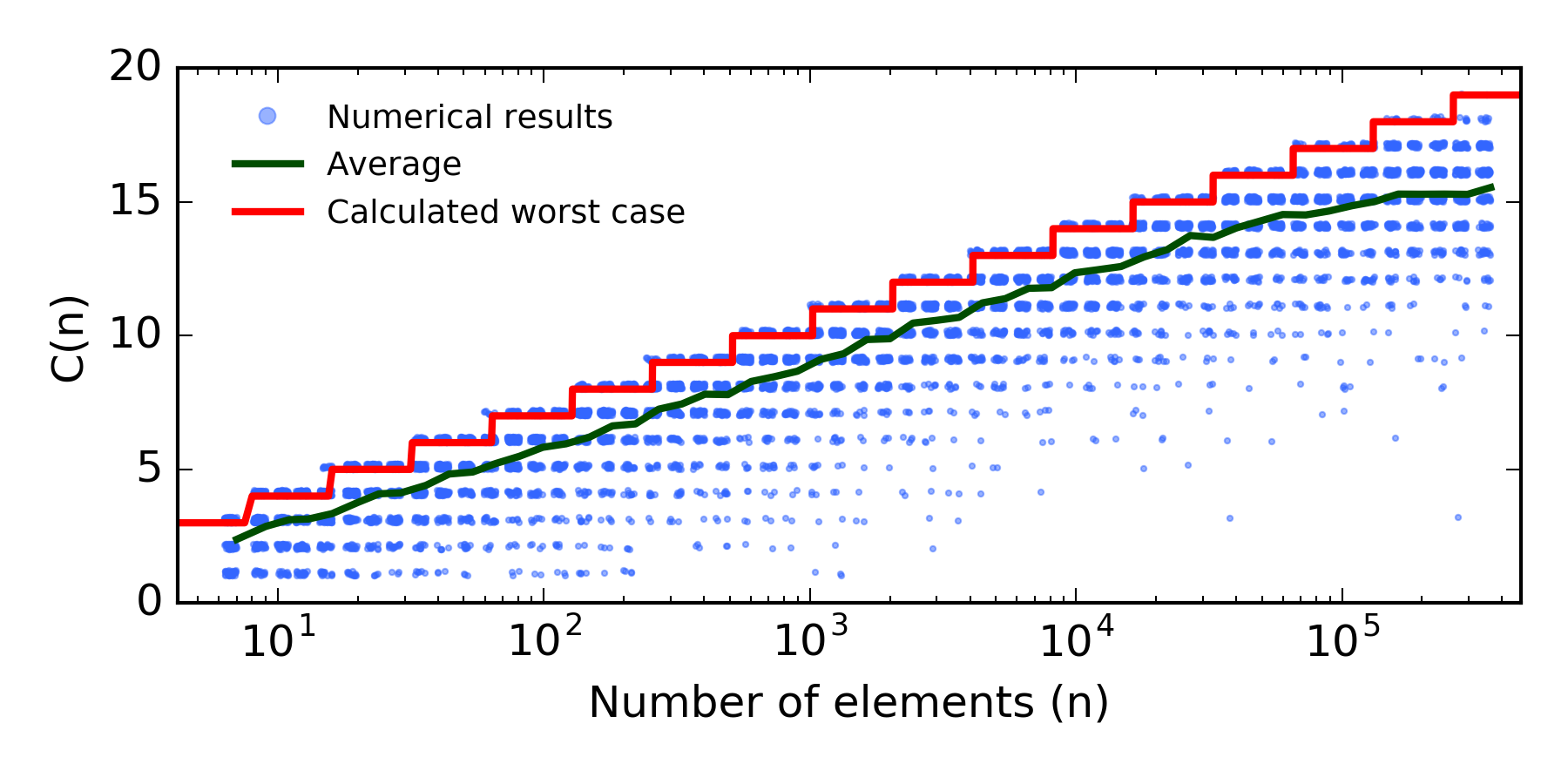
In the plot above, the many blue dots represent all the different numbers of iterations used in each of the 300 different arrays tested. To help visualize where these dots lie more frequently, I used a small jitter and alpha-transparency. The final equation for $C(n)$ always estimates the worst case, scaling linearly in this log-linear plot. As expected, the average however is slightly smaller than the worst case, although not much. If you want to try with more than $10^6$ elements, the script may take a few minutes, but the linear trend continues. Note that, for higher sizes, the number of repetitions must also grow to guarantee a reasonable estimation of the average complexity. To reproduce this numerical test, you can use the Python script below.